|
Jiaxiang Cheng I am a Researcher at Tencent HY, working with Heng Wang in the Video World Foundation Model Team. Previously, I worked with Qinglin Lu in the Video Application Model Team, and was a Research Intern at ByteDance Intelligent Creation Team, collaborating with Jie Wu. I received my Master's degree in Artificial Intelligence from Beihang University in 2025. I am currently exploring Video World Models. My research interests center on Diffusion Distillation and Preference Alignment. Welcome to discuss, feel free to reach out at jiaxiangcc@gmail.com. |
|
News
|
Publications |
|
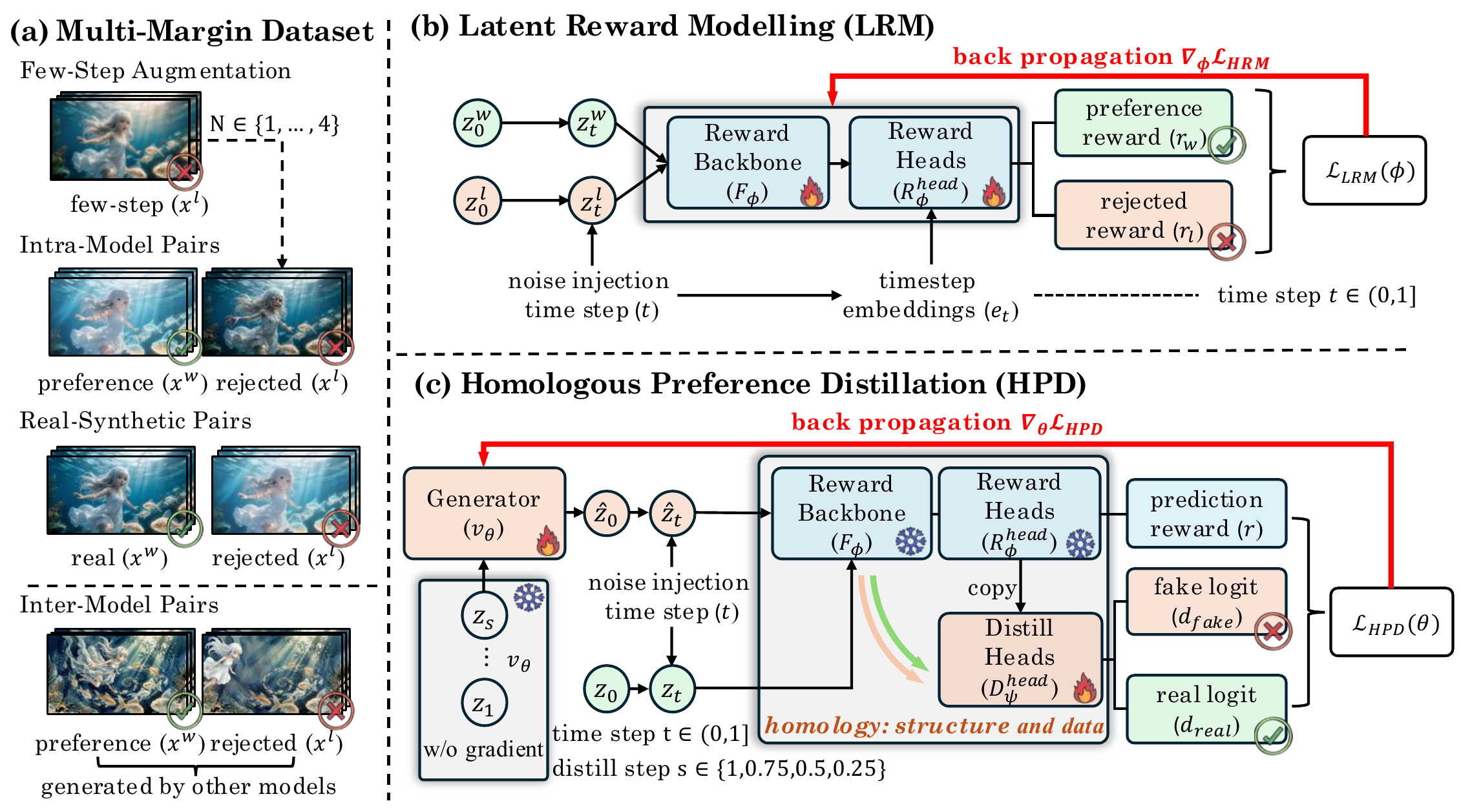
Reward Lightning: Fast Video Generation via Homologous Preference Distillation
Jiaxiang Cheng, Bing Ma, Xuhua Ren, Kai Yu, Peng Zhang, Tianxiang Zheng, Qinglin Lu European Conference on Computer Vision (ECCV), 2026 Project Page / arXiv A framework that jointly achieves preference alignment and acceleration for video diffusion models within a shared latent representation space. |

|
Implicit Preference Alignment for Human Image Animation
Yuanzhi Wang, Xuhua Ren, Jiaxiang Cheng, Bing Ma, Kai Yu, Tianxiang Zheng, Qinglin Lu, Zhen Cui International Conference on Machine Learning (ICML), 2026 Code / arXiv A preference alignment framework for human image animation that eliminates the need for paired preference data. |
|
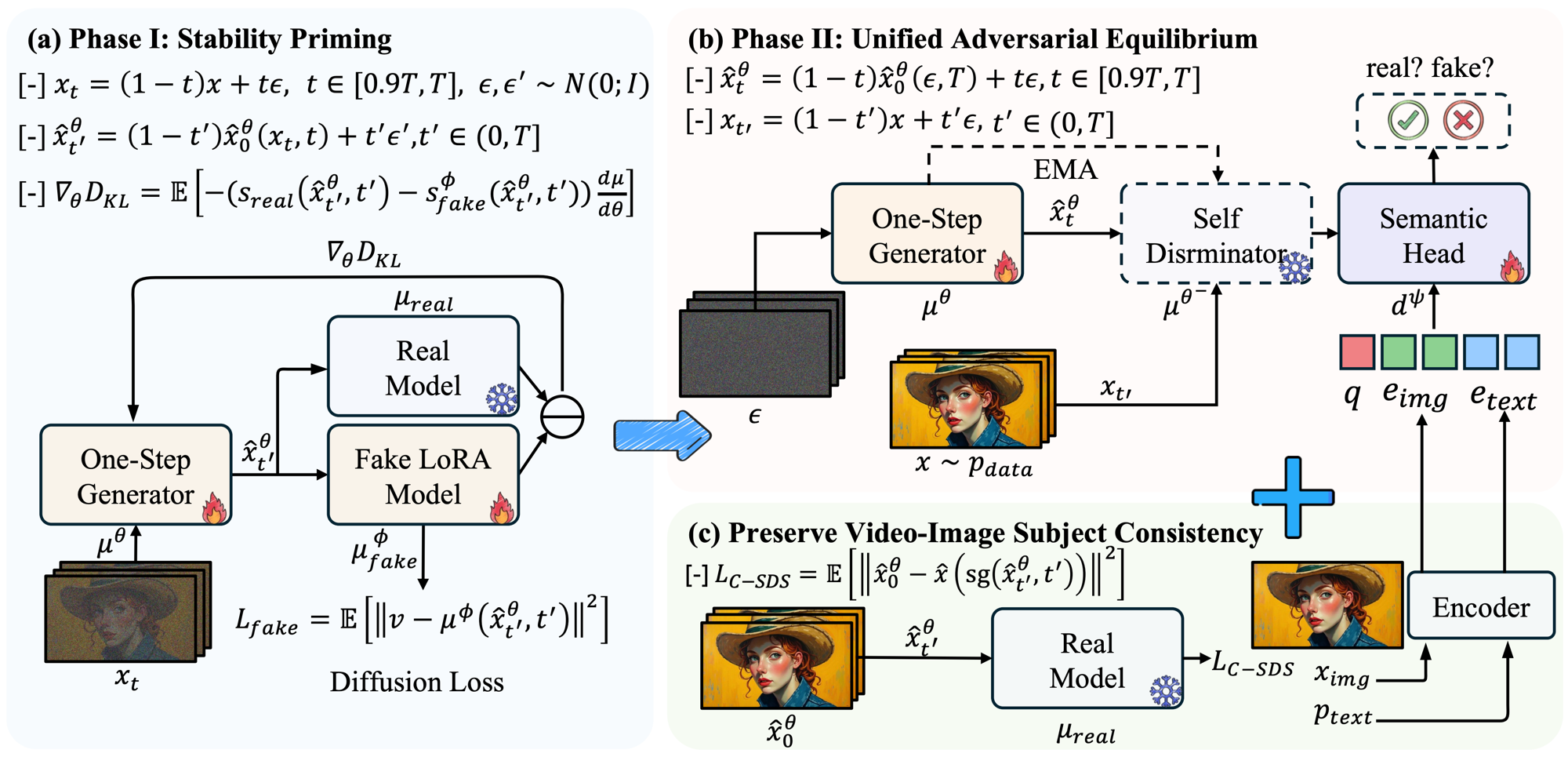
Phased One-step Adversarial Equilibrium for Video Diffusion Models
Jiaxiang Cheng, Bing Ma, Xuhua Ren, Hongyi Henry Jin, Kai Yu, Peng Zhang, Wenyue Li, Yuan Zhou, Tianxiang Zheng, Qinglin Lu AAAI Conference on Artificial Intelligence (AAAI), 2026 Project Page / arXiv A novel phased adversarial training framework for one-step video generation with diffusion models. |
|
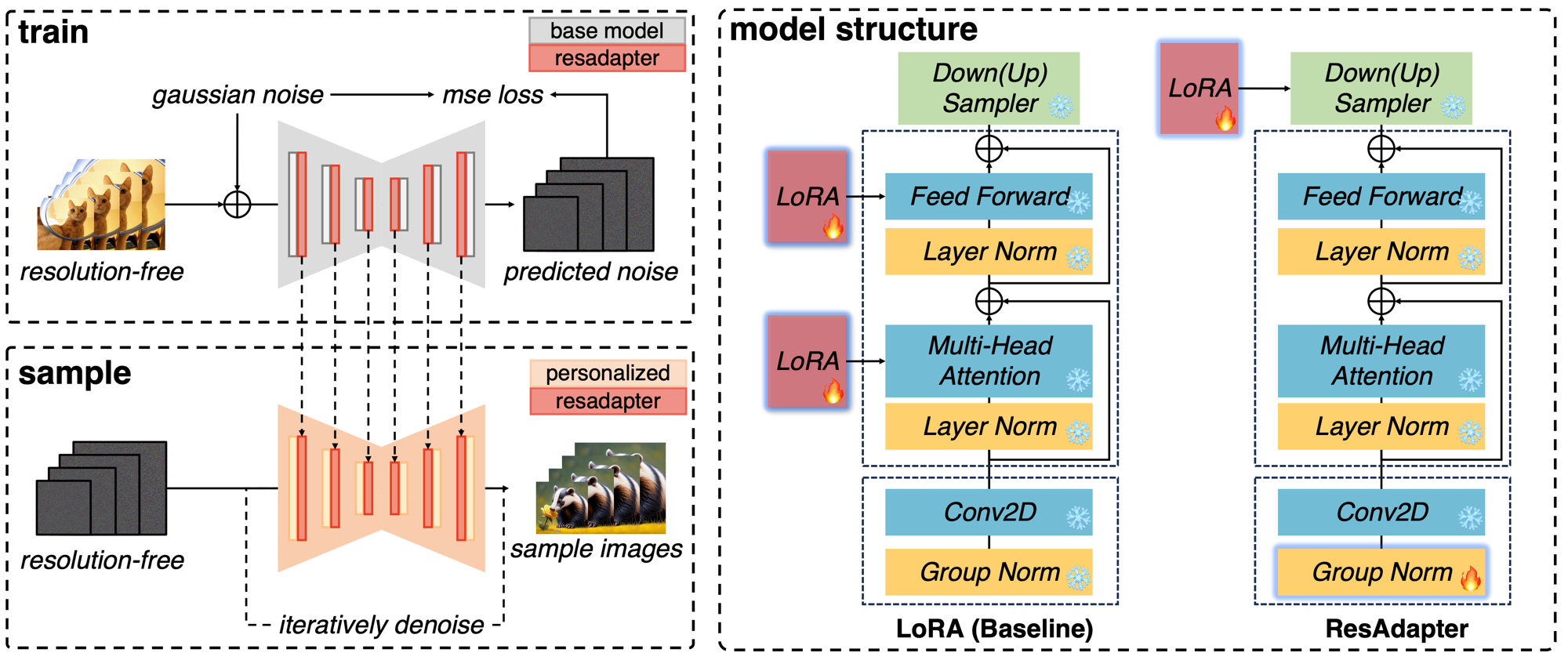
ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models
Jiaxiang Cheng, Pan Xie, Xin Xia, Jiashi Li, Jie Wu, Yuxi Ren, Huixia Li, Xuefeng Xiao, Min Zheng, Lean Fu AAAI Conference on Artificial Intelligence (AAAI), 2025 Project Page / Code / arXiv A plug-and-play resolution adapter for diffusion models that enables arbitrary resolution generation without retraining. |
Preprints |
|
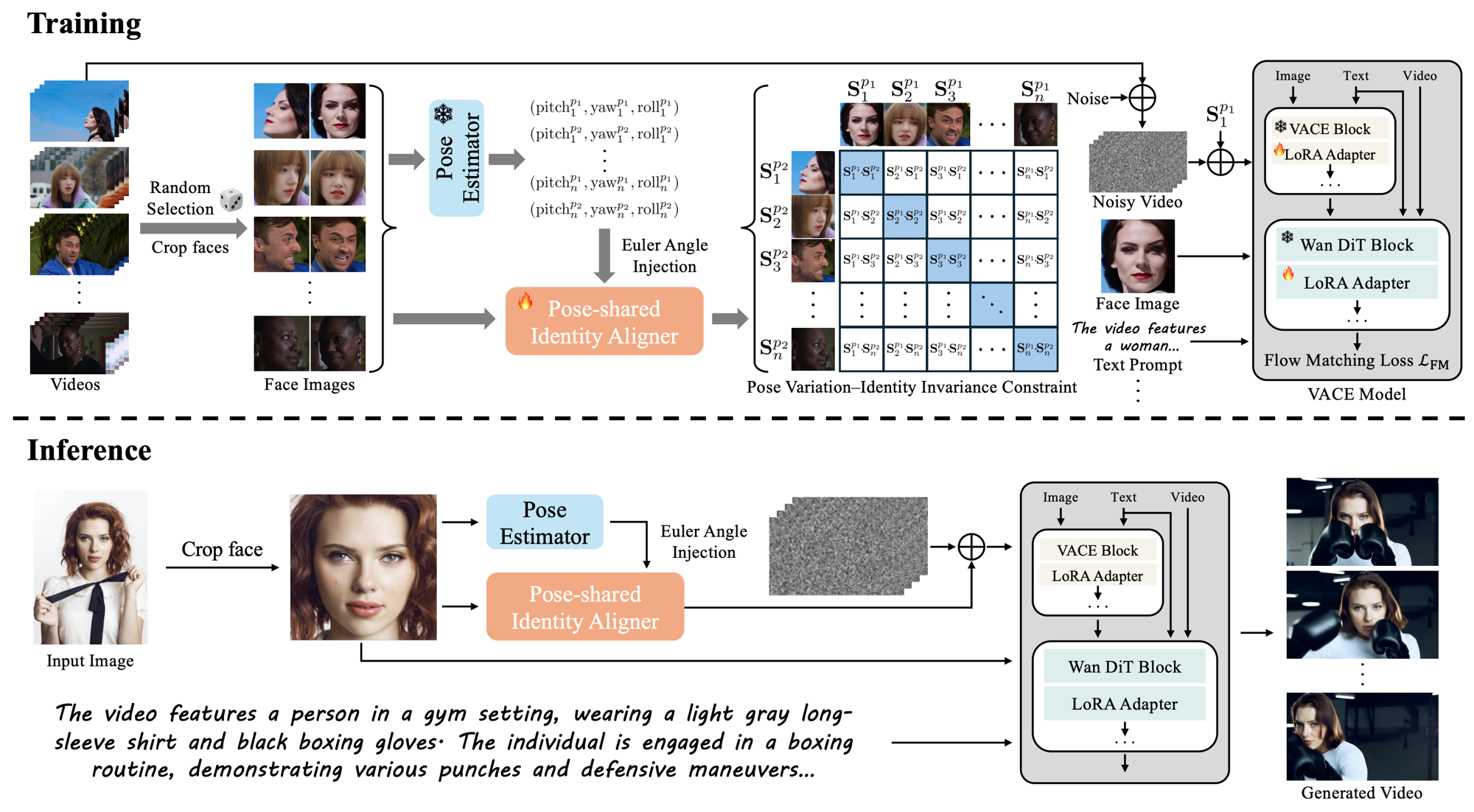
FaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation
Yuanzhi Wang, Xuhua Ren, Jiaxiang Cheng, Bing Ma, Kai Yu, Sen Liang, Wenyue Li, Tianxiang Zheng, Qinglin Lu, Zhen Cui arXiv, 2026 arXiv A pose-faithful approach for preserving facial identity in text-to-video generation. |
|
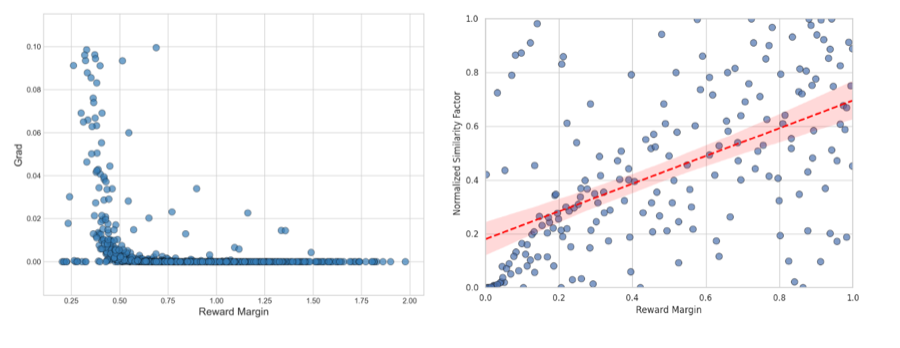
Beyond Reward Margin: Rethinking and Resolving Likelihood Displacement in Diffusion Models via Video Generation
Ruojun Xu, Yu Kai, Xuhua Ren, Jiaxiang Cheng, Bing Ma, Tianxiang Zheng, Qinglin Lu arXiv, 2025 arXiv A study revealing and resolving likelihood displacement in diffusion preference optimization for video generation. |
|
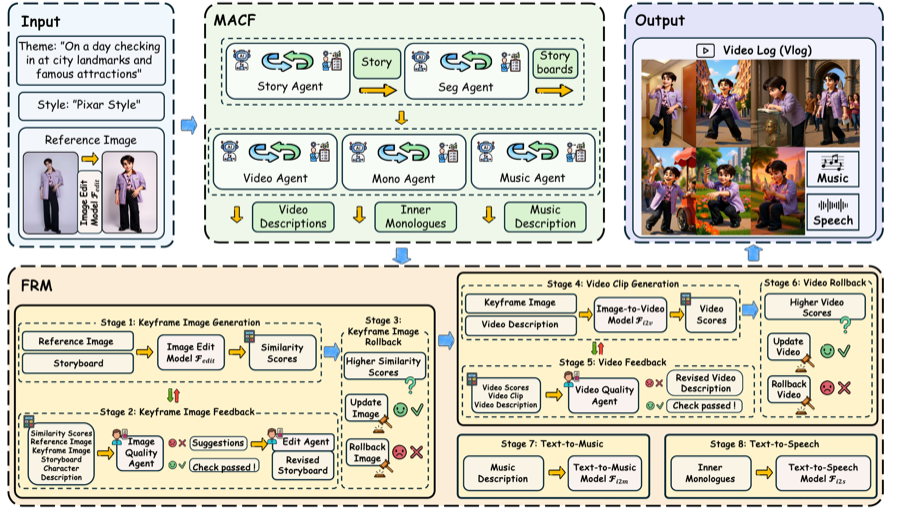
PersonaVlog: Personalized Multimodal Vlog Generation with Multi-Agent Collaboration and Iterative Self-Correction
Xiaolu Hou, Bing Ma, Jiaxiang Cheng, Xuhua Ren, Kai Yu, Wenyue Li, Tianxiang Zheng, Qinglin Lu arXiv, 2025 Project Page / arXiv A multi-agent framework for personalized multimodal vlog generation with iterative self-correction. |
|
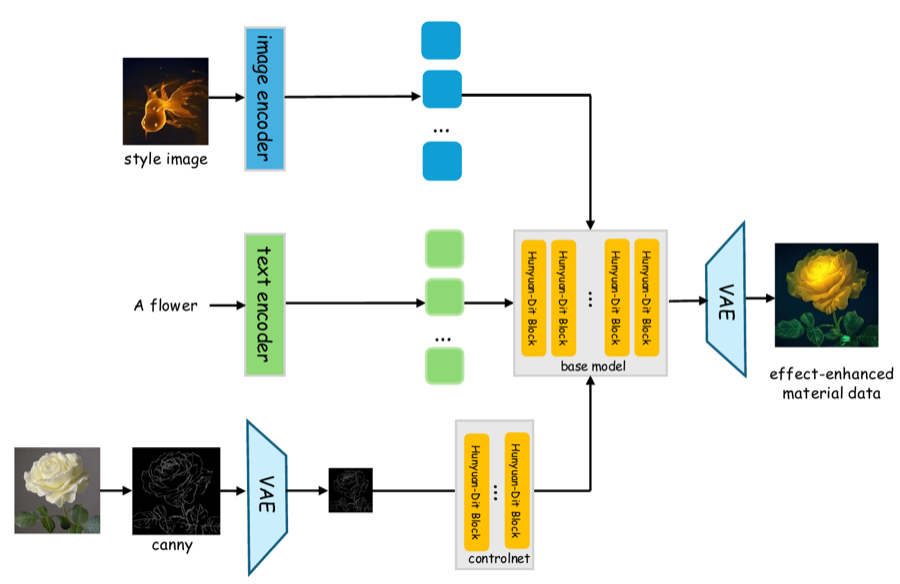
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
Ruihuang Li, Caijin Zhou, Shoujian Zheng, Jianxiang Lu, Jiabin Huang, Comi Chen, Junshu Tang, Guangzheng Xu, Jiale Tao, ..., Jiaxiang Cheng, et al. Technical Report, 2025 Code / arXiv An industrial-grade model suite for game image and video asset creation. |
|
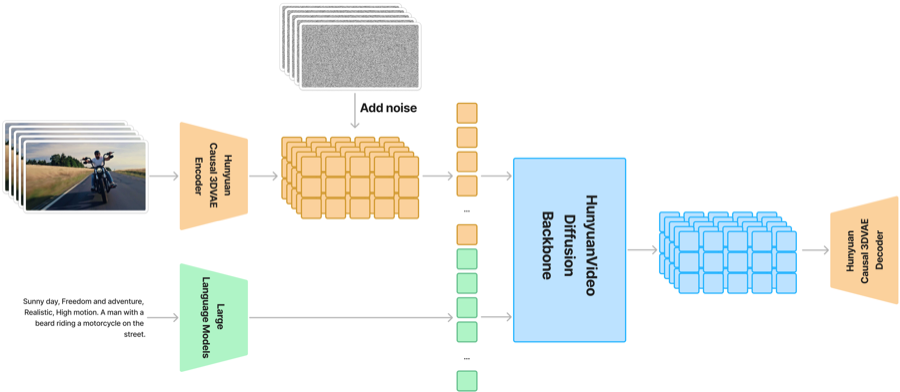
HunyuanVideo: A Systematic Framework for Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, ..., Jiaxiang Cheng, et al. Technical Report, 2024 Code / arXiv A systematic framework for training and deploying large-scale video generative models. |
Education
|
Experience
|
|
|
© Jiaxiang Cheng | Last updated: July, 2026